The justification of induction is probably the most discussed topic in epistemology: no way that a few lines blog can solve it but the idea is that some nice insight may be obtained with a simple derivation based on the notion of mean-squared estimation error. In particular we address here the (somewhat puzzling) no-free-lunch statement (by Wolpert here)) about the non-superiority of cross-validation wrt anti-cross-validation strategies if no assumption about the target distribution is made.
The derivation shows that, if it may indeed happen that an anti cross-validation (or non inductive) strategy outperforms a cross-validation (or inductive) strategy, this requires however a sort of favorable “non-inductive” bias.
Suppose that the target is the quantity 

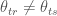
So the first issue is to define properly what we mean by inductive approach. I will define by inductive approach a learning strategy whose goal is to minimise the mean-squared error on the basis of the training-set, i.e. the quantity
MSE
![_{tr}(\theta_{tr})= E_{D_{N}}[ (\theta_{tr} - \hat{\boldsymbol \theta})^2]](https://s0.wp.com/latex.php?latex=_%7Btr%7D%28%5Ctheta_%7Btr%7D%29%3D+E_%7BD_%7BN%7D%7D%5B+%28%5Ctheta_%7Btr%7D+-+%5Chat%7B%5Cboldsymbol+%5Ctheta%7D%29%5E2%5D+&bg=ffffff&fg=444444&s=0&c=20201002)
where 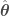

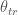
In the same vein, I will define as non-inductive any strategy which does not target the minimisation of the mean-squared error in the training setting. In this definition, cross-validation is an inductive strategy while anti cross-validation (defined by Wolpert here) is non-inductive. According to Wolpert for any target off-training scenario where cross-validation is superior to anti cross-validation, it is possible to define another scenario where the reverse is true as well.
Let us analyse this statement from a MSE perspective where both 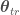
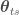
Let us write the off training MSE as
MSE
![_{off}= E_{D_{N}, \theta_{ts}, \theta_{tr}}[ ({\boldsymbol \theta}_{ts} -\hat{\boldsymbol \theta})^2]](https://s0.wp.com/latex.php?latex=_%7Boff%7D%3D+E_%7BD_%7BN%7D%2C+%5Ctheta_%7Bts%7D%2C+%5Ctheta_%7Btr%7D%7D%5B+%28%7B%5Cboldsymbol+%5Ctheta%7D_%7Bts%7D+-%5Chat%7B%5Cboldsymbol+%5Ctheta%7D%29%5E2%5D&bg=ffffff&fg=444444&s=0&c=20201002)
It follows
MSE
![_{off}= E_{D_{N}, \theta_{ts}, \theta_{tr}}[ ({\boldsymbol \theta}_{ts} - {\boldsymbol \theta}_{tr} + {\boldsymbol \theta}_{tr} - \hat{\boldsymbol \theta})^2] = E_{\theta_{ts}, \theta_{tr}}[ ({\boldsymbol \theta}_{ts} - {\boldsymbol \theta}_{tr})^2] + E_{\theta_{tr}}[{ \textbf{MSE}}_{tr}] - 2C](https://s0.wp.com/latex.php?latex=_%7Boff%7D%3D+E_%7BD_%7BN%7D%2C+%5Ctheta_%7Bts%7D%2C+%5Ctheta_%7Btr%7D%7D%5B+%28%7B%5Cboldsymbol+%5Ctheta%7D_%7Bts%7D+-+%7B%5Cboldsymbol+%5Ctheta%7D_%7Btr%7D+%2B+%7B%5Cboldsymbol+%5Ctheta%7D_%7Btr%7D+-+%5Chat%7B%5Cboldsymbol+%5Ctheta%7D%29%5E2%5D+%3D+E_%7B%5Ctheta_%7Bts%7D%2C+%5Ctheta_%7Btr%7D%7D%5B+%28%7B%5Cboldsymbol+%5Ctheta%7D_%7Bts%7D+-+%7B%5Cboldsymbol+%5Ctheta%7D_%7Btr%7D%29%5E2%5D+%2B++E_%7B%5Ctheta_%7Btr%7D%7D%5B%7B+%5Ctextbf%7BMSE%7D%7D_%7Btr%7D%5D+-+2C++&bg=ffffff&fg=444444&s=0&c=20201002)
where the first term represents the amount of drift from the training setting to the test setting (which inevitably deteriorates the accuracy), the second term is the average training MSE and the third term is a covariance term
![C= E_{D_{N}, \theta_{ts}, \theta_{tr}} [ ({\boldsymbol \theta}_{ts} - {\boldsymbol \theta}_{tr}) (\hat{\boldsymbol \theta}- {\boldsymbol \theta}_{tr}) ]](https://s0.wp.com/latex.php?latex=C%3D+E_%7BD_%7BN%7D%2C+%5Ctheta_%7Bts%7D%2C+%5Ctheta_%7Btr%7D%7D+%5B+%28%7B%5Cboldsymbol+%5Ctheta%7D_%7Bts%7D+-+%7B%5Cboldsymbol+%5Ctheta%7D_%7Btr%7D%29+%28%5Chat%7B%5Cboldsymbol+%5Ctheta%7D-+%7B%5Cboldsymbol+%5Ctheta%7D_%7Btr%7D%29++%5D+&bg=ffffff&fg=444444&s=0&c=20201002)
This derivation shows that inductive approaches outperform non-inductive approaches (i.e. approaches which do not aim at minimising MSE
Now such covariance term is indeed related to the alignement between estimator (or hypothesis) and test target. As stated by the no-free-lunch theorem it may indeed happen that non-induction strategies are more accurate than inductive ones. However, assuming that would necessarily imply that the covariance term is positive and this can only happen if the non-inductive approach has some proper “non-inductive” bias. It appears then interesting to see that, like the superiority of a learning approach over another relies on the choice of a proper (or lucky) inductive bias, the superiority of a non-inductive approach over an inductive requires a similar “strong” assumption. For instance if you knew in advance that there will be a significant downward shift of
My 5cent (reassuring) conclusion is then that, if no assumption about the knowledge of the test distribution is available and a MSE derivation is considered, inductive approaches necessarily outperform non-inductive ones.
